Metadata Registry
The Metadata Registry View allows authorized users to define a system-wide catalog of known remote datasets, which are described by means of a combination of (metadata) vocabularies, including DCAT, LIME/VoID, FOAF and DCMI Metadata Terms. Additionally, the Metadata Registry uses a small RDF vocabulary to represent metadata that falls beyond the scope of the standard vocabularies that have been mentioned previously.
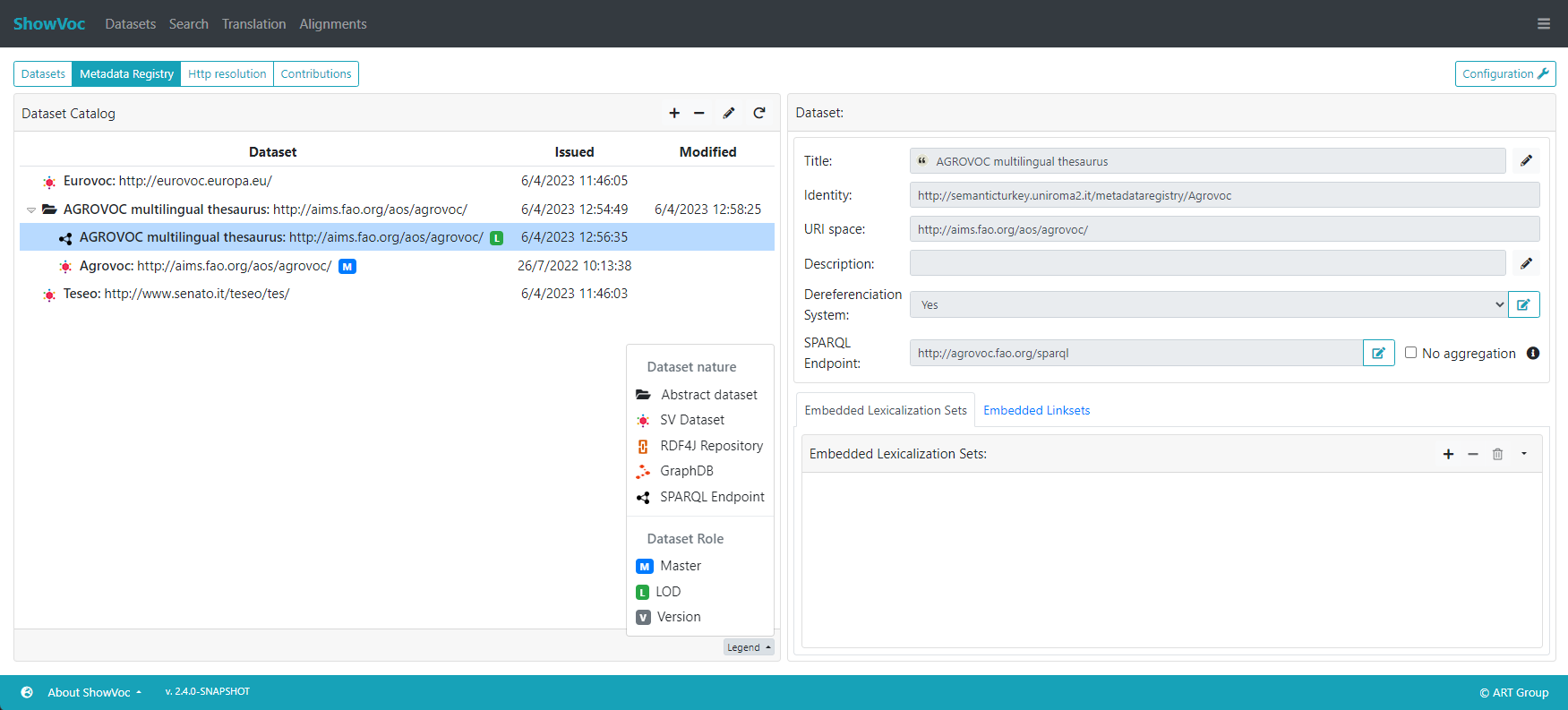
The UI is mainly composed by two panels: the left panel (Dataset Catalog) lists all the datasets defined in the system, while the right one (Dataset) shows details about the selected dataset.
Two kinds of datasets can be distinguished: dataset abstractions and concrete datasets. A dataset abstraction is kind of like a general reference to a dataset, that gives some identity to it despite its many realizations. A concrete dataset identifies a specific version (in a broad sense) of the dataset. It could be a numeric release version (e.g. 5.2), or some particular evolving datasets, e.g. the master version of the dataset being edited on VocBench, or the LOD Dataset with its SPARQL endpoint.
The Dataset Catalog is represented as a tree. In this tree, we can have, as roots, both abstract datasets and concrete datasets. A dataset abstractionm is always a root while a concrete dataset is a root if it has no link to an abstract dataset. When an abstract dataset is expanded its linked concrete datasets are listed.
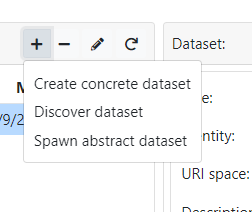
In the Dataset Catalog panel, through the buttons at the top, it is possible to create and delete datasets. There are different ways for creating a dataset:
-
Create abstract dataset: allows to define a dataset abstraction providing the following information:
- Name: the short name associated with the dataset abstraction: it will be used to generate names of resources associated with it in the Metadata Registry;
- URI Space: a URI that is a common string prefix of all entity URIs in the dataset. In other words, the dataset namespace;
- Title: title(s) of the dataset (optional);
- Description: description(s) of the dataset;
-
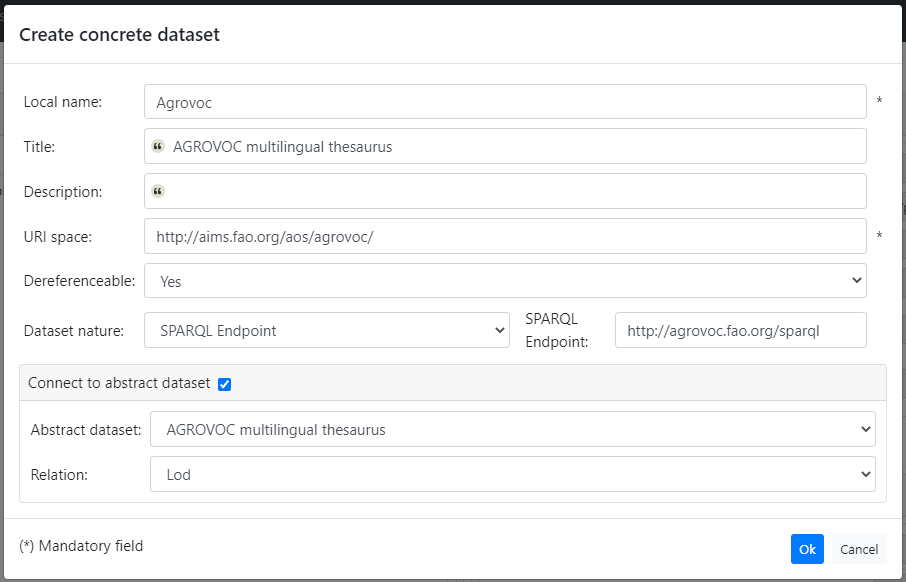
Create concrete dataset: allows to define a new concrete dataset providing the following information:
- Name: the local name of the IRI that will identify the dataset in the Metadata Registry;
- Title: title of the dataset (optional);
- Description: an optional description of the dataset;
- URI Space: a URI that is a common string prefix of all entity URIs in the dataset. In other words, the dataset namespace;
- Dereferenceable: tell if the IRI of the resources defined by the dataset can be dereferenced (to obtain their RDF description)
- Nature: determines the nature of the dataset. The available options are:
- Project: the dataset has a corrispective project in VB. If this option is chosen, a further selector allows you to specify the refence to a VB project. Note: a dataset of a project is automatically created when a project is profiled, so rarely you will need to manually create a dataset with this nature.
- RDF4J HTTP Repository: dataset hosted on an RDF4J repository which exposes public API and a SPARQL endpoint;
- GraphDB Repository: dataset hosted on an GraphDB repository which exposes public API and a SPARQL endpoint;
- SPARQL Endpoint: dataset accessible through a public SPARQL endpoint.
-
Attach to abstract dataset: optionally the concrete dataset can be attached to an already existing abstract dataset. If this option is checked, you need to select the abstract dataset to attach to and the relation among:
- Master: the master copy of a dataset being edited in production;
- Lod: stands for Linked Open Dataset and it’s the official endpoint for the dataset;
- Has Version: a particular version (intended specifically as a release version, e.g. 5.3) with a certain version info and description.
- Connect to abstract dataset: allows the connection of a root concrete dataset (the one selected in the tree) to an existing abstract dataset. This action requires to specify the same info already seen for the attach to abstract dataset option seen above, so you must specify an abstract dataset and the relation between the concrete and the abstract.
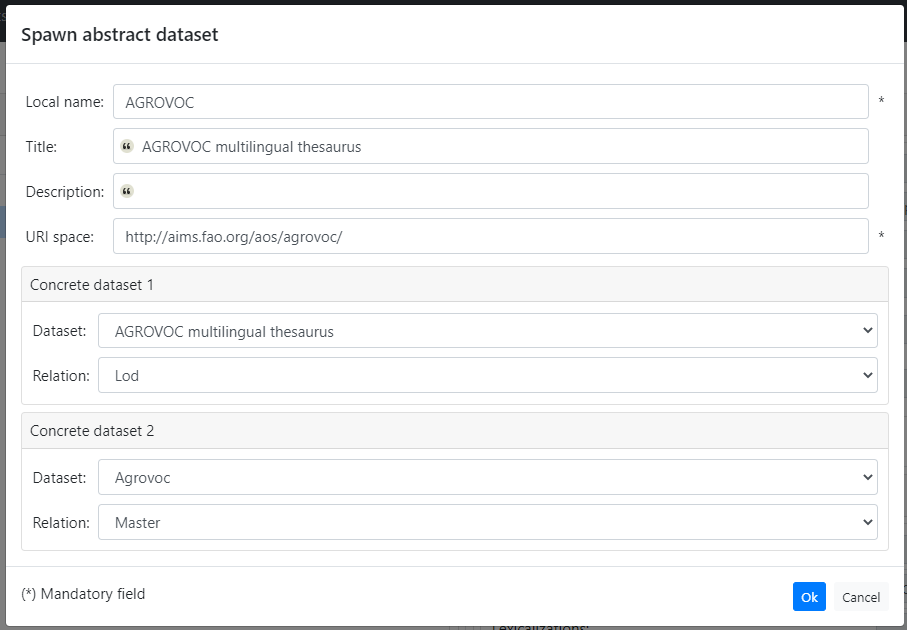
- Spawn new abstract dataset: creates an abstract dataset by merging two existing concrete. The abstract dataset needs a name, optionally a title and a description, and a URI space. For both the concrete datasets you need to specify the relation with the abstract one.
- Discover dataset: allows to define a new dataset by letting the system discover it simply providing an IRI, which can identify:
- a resource defined by the dataset (e.g. http://aims.fao.org/aos/agrovoc/c_1071). If available, the system follows the link to the void:Dataset - expressed through the void:inDataset property - describing the containing dataset)
- a void:Dataset, a resource being a sort of metadata proxy for the dataset of interest (e.g. http://aims.fao.org/aos/agrovoc/void.ttl#Agrovoc)
- an owl:Ontology (e.g. http://xmlns.com/foaf/0.1/)
Currently, the discovery process does not include the use of a profiling mechanism to infer missing metadata, such as the lexicalization asset of the dataset. If not found (e.g. in the VoID description of them dataset), this information can be added later as discussed below.
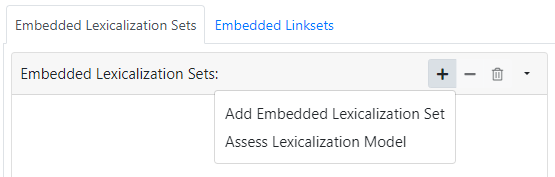
The Dataset panel shows details about the selected dataset and allows you to edit some of them. It allows you also to provide information about the embedded lexicalization sets. These are called embedded, because they are part of the dataset itself, differently from lexicalizations that are shipped as a third-party, autonomous dataset.
Also in this case there are two ways to define lexicalization sets:
- Add Embedded Lexicalization Set: allows to provide manually information and statistics about a lexicalization set of the dataset
- Asses Lexicalization Model: let the system discover the lexicalization sets by querying the dataset. In order to exploit this feature it is necessary to provide a SPARQL Endpoint for the given dataset. the discovery uses the MAPLE framework, and in summary tries all known lexicalization model to find the one that best fit the available lexicalizations. To reduce the stress on the SPARQL endpoint (which may not support the complex aggregated queries that would have been necessary), the discovery process does not produce detailed statistics (e.g. the percentage of the resources that have been lexicalized), and it uses an approximated algorithm: it tries to find a given number of resources (currently 100) that have at least one lexicalization, and then uses that sample to determine the available languages.