




Contributions Management
Introduction
When a user submits a contribution request an email notification is sent to the administrator. Then the administrator can examine the submitted requests in a dedicated page: the Contributions manager.
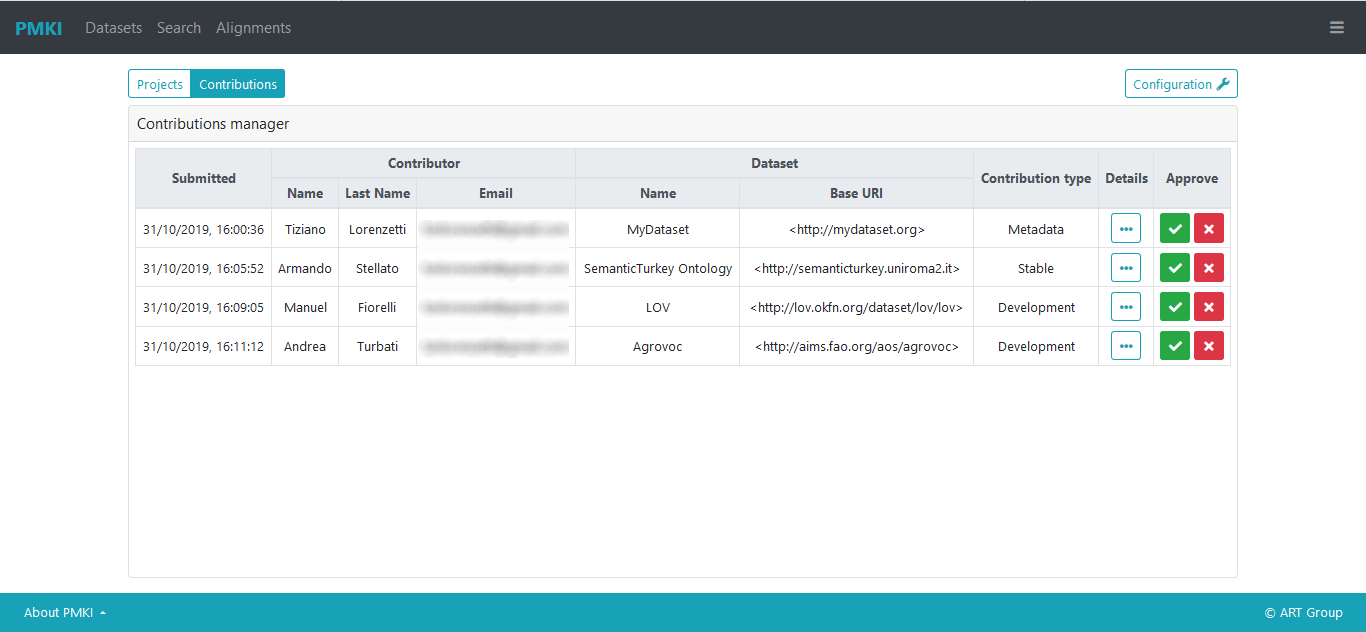
The contributions table
A table lists all the submitted requests waiting to be evaluated. For each request are shown: the data of submission, basic information about the contributor, the name and the base URI of the dataset envolved in the contribution and the contribution type.
The last two columns of the table are the more significant. The button under the Details column opens a modal dialog that allows to inspect all the information provided by the contributor during the request submission. The figure below shows an example with details about a stable resource contribution.
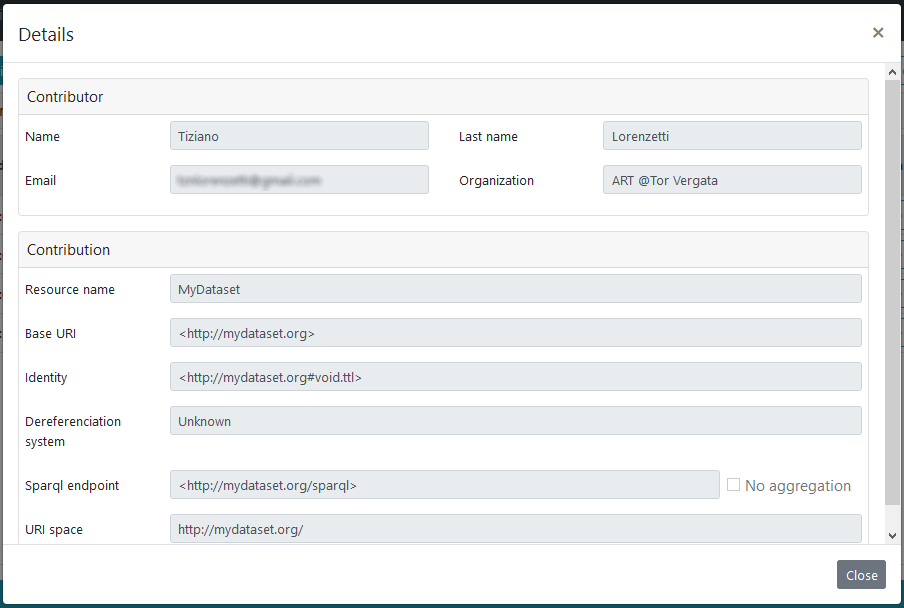
Contribution approval
The column Approve provide two buttons: the green one allows to accept the contribution, while the red one to reject it. The rejection of a request causes the removal of the same from the table, and contextually an email is sent to the contributor in order to inform about the outcome of the evaluation. What happens when a request is accepted depends on the contribution type.
When a metadata contribution is accepted, a simple dialog asks for confirmation from the administrator. In case the administrator accepts, the metadata proposed in the contribution are then written into the system Metadata Registry.
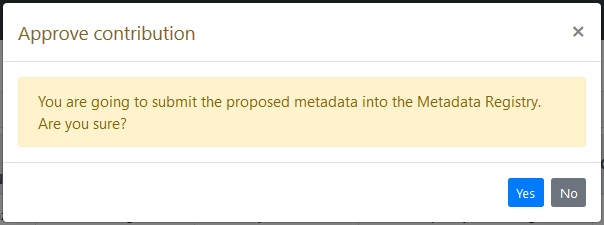
When a resource contribution is approved, be it a about stable resource or about one to develop, a new dataset must be created.
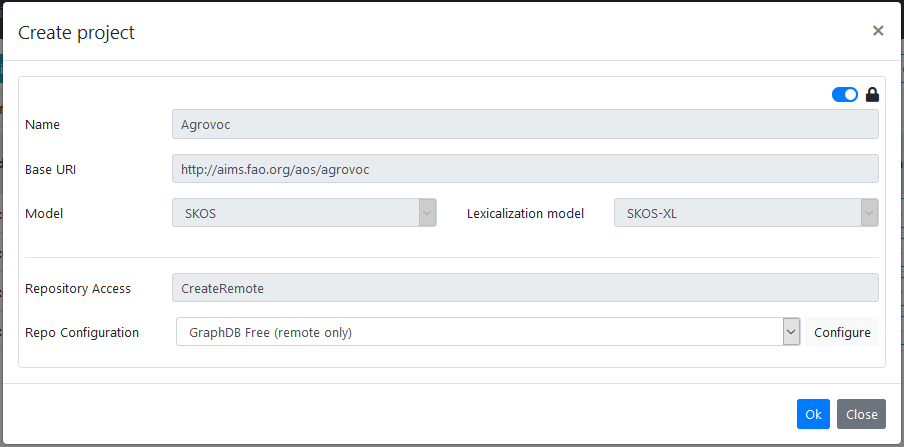
A modal dialog prompts a dataset creation form with the following fields:
- Name: the name of the dataset. Any name which can be stored as a folder in the file system is a valid dataset name;
- Base URI: any valid ontology URI is accepted. If the URI ends with no trailing # nor /, the default namespace will end with a #. If the URI ends with /, the default namespace will be the same as the baseuri;
- Model: the data model adopted in the dataset. It can be SKOS (for thesauri) or OntoLex (for lexicons);
- Lexicalization model: it can be RDFS, SKOS, SKOS-XL or OntoLex depending on the lexicalization model you want to adopt for your data;
-
Repository Access: one of:
- CreateLocal: creates a local data repository;
- CreateRemote: creates a repository on a remote triple store;
- Repo Configuration: configuration of the repository. Currently there are configurable settings for RDF4J and GraphDB stores.
The fields Name, Base URI, Model and Lexicalization model are pre-filled with the values provided by the contributor (the dataset name is eventually sanitized) and these values are readonly. The administrator anyway can enable the editing of these fields by unlocking them through the switch in the top right corner.
In case of development resource contribution, the selection of the Repository Access is forced to CreateRemote and cannot be changed. Recalling that in this case the dataset is created on a remote configured instance of VocBench, a RemoteAccessConfiguration needs to be stored on it (in case multiple configurations are found, the first will be used).
By clicking on the OK button, the new dataset is created and, if no error occurs during the procedure, an email notification is sent to the contributor containing details on how to proceed and complete the contribution process.